컴퓨터 구조에는 크게 4가지로 정의할 수 있다.
1. 프로세서(CPU)
- CPU는 중앙처리장치(Central Processing Unit)의 약자로, 컴퓨터의 중심(뇌)이 되는 가장 중요한 하드웨어입니다. CPU는 우리가 컴퓨터로 하는 모든 작업의 중심에서 명령을 처리하고 결과를 제공합니다.
CPU의 구성 요소
- 산술 논리 장치(ALU)
ALU는 Arithmetic Logic Unit, 즉 산술 논리 장치로, 숫자를 계산하거나 데이터를 비교하는 일을 해요.
- 산술 논리 장치(ALU)
- 제어 장치(CU)
CU는 CPU의 지휘관이에요.
프로그램 명령어를 해석하고, 어떤 작업을 할지 ALU와 메모리에 지시합니다.
CPU가 제대로 일하도록 모든 흐름을 조정하는 역할을 해요.
- 제어 장치(CU)
✅ 프로그램 동작 실행 순서
1. 사용자가 카카오톡 앱을 실행하면, 운영체제(OS)의 커널(Kernel)이 하드디스크(저장소)에 있는 카카오톡 프로그램 파일을 메모리(RAM)에 적재합니다.
2. 이때 해당 프로그램은 프로세스(Process)로 변환되어 실행 준비를 마칩니다.
3. CPU는 이 프로세스의 명령어를 하나씩 가져오고(fetch), CU(Control Unit, 제어 장치)는 이 명령어들을 해석(Decode)하여
4. ALU(산술 논리 장치)나 레지스터 등이 실제 연산을 수행(execute)할 수 있도록 지시합니다.- 레지스터(Register)
레지스터는 CPU 내부에 있는 초고속 메모리예요.
- 레지스터(Register)
계산에 필요한 데이터를 잠깐 저장하거나 연산 결과를 임시로 보관하는 역할을 합니다.
속도가 정말 빠르기 때문에 연산 과정에서 매우 중요해요.
레지스터의 종류
- 범용 레지스터 (General Purpose Register)
데이터를 저장하고 계산에 사용되는 가장 기본적인 레지스터입니다. 예: 5 + 3을 계산할 때, 두 숫자와 결과를 범용 레지스터에 저장합니다.
- 명령어 레지스터 (Instruction Register)
현재 실행 중인 명령어를 저장하는 레지스터예요. CPU는 이 명령어를 읽고 작업을 수행합니다.
- 프로그램 카운터 (Program Counter, PC)
다음에 실행할 명령어의 주소를 저장합니다. 프로그램이 순서대로 실행되도록 돕는 역할을 해요.
- 상태 레지스터 (Status Register)
연산 결과의 상태를 저장해요. 예: 연산 결과가 0인지, 음수인지 등의 정보를 기록해서 다음 작업에 활용합니다.
※ 레지스터와 RAM(메모리)의 차이

✅ 프로그램 카운터(PC)의 정의
- PC란 레지스터의 한 종류로서 특수한 역할을 맡는다. (명령어 주소를 저장하는)
- 프로그램 카운터(PC)는 CPU에서 현재 실행 중인 명령어의 주소를 추적하는 중요한 레지스터예요. 쉽게 말하면, CPU가 어디까지 작업을 했는지를 알려주는 주소표시기와 같은 역할을 해요.
- PC의 기본 역할
CPU는 명령어를 순차적으로 실행하는데, 이때 프로그램 카운터(PC)는 현재 명령어의 주소를 가리키고 있어요.
프로그램 카운터는 메모리 주소를 가리키고, CPU가 실행할 명령어를 찾아서 실행하죠.
2. RAM(Random Access Memory)
- RAM(Random Access Memory)은 컴퓨터에서 임시로 데이터를 저장하고 빠르게 접근할 수 있는 기억 장치예요.
- RAM은 흔히 주기억 장치라고 불리며, 컴퓨터가 작업을 수행할 때 필요한 데이터를 저장하고 빠르게 꺼내 쓰는 역할을 해요.
- 하지만 컴퓨터가 꺼지면 RAM에 저장된 데이터는 모두 사라지기 때문에, ‘휘발성 메모리’라고도 불립니다.
- 쉽게 말해, RAM은 컴퓨터가 “지금 하고 있는 작업”을 처리하는 공간이에요.
RAM의 기본 구조
- 읽기(Reading)
CPU가 필요한 데이터를 요청하면, RAM은 그 데이터를 빠르게 읽어서 CPU로 보냅니다.
- 쓰기(Writing)
CPU가 저장해야 할 데이터를 RAM에 빠르게 기록합니다.RAM의 역할
- RAM은 컴퓨터에서 현재 작업 중인 데이터와 실행 중인 프로그램의 내용을 저장합니다.
- RAM이 없다면, 컴퓨터는 매번 데이터를 하드디스크에서 가져와야 해서 속도가 엄청 느려질 거예요.RAM의 종류
1. DRAM (Dynamic RAM)
- 저렴하고 대용량으로 사용할 수 있어요.
- 데이터를 유지하려면 주기적으로 새로고침(refresh)이 필요합니다.
- 용도: 일반적인 컴퓨터의 주메모리.
2. SRAM (Static RAM)
- DRAM보다 빠르고, 새로고침 없이 데이터를 유지할 수 있어요.
- 가격이 비쌉니다.
- 용도: 고속 캐시 메모리 등 속도가 중요한 영역.
3. SDRAM (Synchronous DRAM)
- DRAM의 일종으로, CPU의 클럭 신호에 맞춰 동작해 더 빠릅니다.
- 용도: 일반적인 PC 메모리로 사용됩니다.※ 메모리 계층 구조의 단계
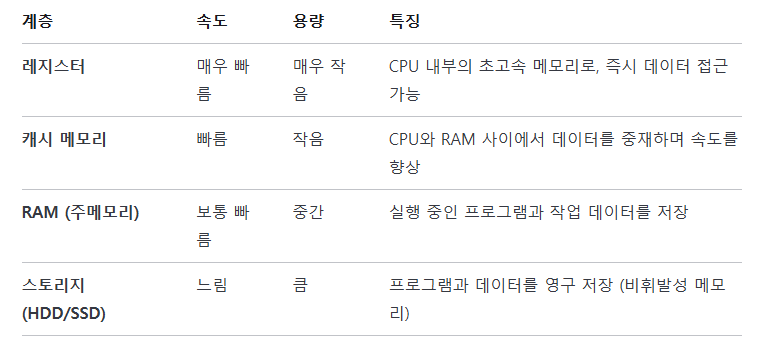
3. 저장장치 (HDD, SSD)
저장장치란 ?
- 저장 장치는 컴퓨터에서 데이터를 영구적으로 저장하는 장치예요.
- 어떤 데이터를 저장할까? 문서, 사진, 동영상, 프로그램 같은 파일들을 보관하죠.
- 만약 저장 장치가 없다면 컴퓨터는 전원을 끄는 순간 모든 데이터를 잃어버리게 될 거예요.
대표적인 저장 장치의 종류
1. HDD (Hard Disk Drive):
- 디스크가 회전하면서 데이터를 저장하는 방식이에요. 오래된 기술이지만 대용량을 저렴하게 제공합니다.
2. SSD (Solid State Drive):
-반도체 칩을 사용해 데이터를 빠르게 저장하고 읽는 최신 기술입니다.HDD와 SSD의 차이점

4. 입출력 장치
입출력 장치란?
- 입출력 장치(I/O Devices)는 컴퓨터와 우리가 데이터를 주고받을 수 있게 해주는 장치예요.
- 입력 장치는 우리가 컴퓨터에 데이터를 넣는 역할을 하고
- 출력 장치는 컴퓨터가 처리한 결과를 우리가 볼 수 있게 해줘요. I/O는 Input(입력)과 Output(출력)의 줄임말이에요.
주요 입력 장치

주요 출력 장치

CS 질문
1. CPU는 어떤 역할을 하나요?
CPU는 Central Processing Unit의 약자로 컴퓨터의 중심 처리 장치로, 프로그램의 명령어를 해석하고 실행하는 역할을 합니다.
내부에는 제어 장치(Control Unit), 산술논리장치(ALU), 레지스터 등으로 구성되어 있으며, 메모리에서 명령어를 가져와 실행 순서를 제어합니다.
꼬리질문 1 : 그럼 ALU와 CU의 차이는 무엇인가요?
- ALU는 Arithmetic Logic Unit으로, 산술 연산(덧셈, 뺄셈)과 논리 연산(and, or)을 수항하는 곳입니다.
- CU는 Control Unit으로, 명령어를 해석해서 ALU나 메모리, 입출력 장치 등에 작업을 지시하는 '지휘자'역할을 합니다.
꼬리질문 2 : 레지스터는 왜 필요한가요?
- 레지스터는 CPU 내부에 있는 매우 작은 고속 메모리입니다.
- 자주 사용하는 데이터를 임시로 저장해서 연산 속도를 빠르게 합니다.
- 레지스터가 없다면 CPU가 연산할 때마다 RAM이나 캐시 메모리까지 접근을 한 후 연산을 시작하게 되는데,
- 이 과정에서 명령어 수행 속도가 급격히 저하되고, 전체 시스템 성능에 병목이 생깁니다.
2. 캐시 메모리는 무엇이고 왜 사용하나요?
- 캐시 메모리는 CPU와 RAM 사이에서 자주 사용하는 데이터를 임시로 저장하는 고속 메모리입니다.
- RAM 접근은 느리기 때문에, 최근 사용된 데이터를 캐시에 두면 CPU가 더 빠르게 접근할 수 있어 성능이 향상됩니다.
- CPU -> 레지스터 -> 캐시 -> RAM 순으로 계층적 구조를 갖습니다.
꼬리질문 1 : 캐시 메모리보다 더 빠른 레지스터가 있는데 레지스터에 등록하고 사용하면 되지 않나?
- 레지스터는 매우 빠르지만 용량이 극히 작고 수가 제한적이기 때문에 모든 데이터를 저장할 수 없습니다.
- 레지스터는 CPU 내부에 있는 소수의 초고속 저장공간으로, 산술 연산, 주소 계산 등에서 즉시 필요한 값만 저장합니다.
- 반면, 캐시 메모리는 레지스터보다는 느리지만 수천 배 더 많은 데이터를 저장할 수 있어서 CPU가 자주 접근하는 데이터를 더 넓게 커버할 수 있습니다.
- 즉, 레지스터는 순간 연산용, 캐시는 반복 접근 데이터를 위한 고속 메모리라는 역할 차이가 있습니다.
꼬리질문 2 : 캐시의 지역성(Locality of Reference)이 뭔가요?
- 캐시가 효과적으로 동작하는 이유는 프로그램 실행 시 데이터 접근에 지역성(Locality)이 존재하기 때문입니다.
- 시간 지역성 : 최근 사용한 데이터는 다시 사용할 가능성이 높음
- 공간 지역성 : 특정 주소 근처의 데이터를 곧 사용할 가능성이 높음, 이런 특성을 기반으로 캐시가 데이터를 미리 불러오거나 보관합니다.
3. 프로세스와 스레드의 차이는 무엇인가요?
- 프로세스는 실행 중인 프로그램의 독립된 단위로 프로그램이 실행되는 순간 프로세스로 변환되며, 각각 고유한 메모리 공간을 가집니다.
- 스레드는 프로세스 내부의 작업 단위로, 같은 프로세스 내 스레드끼리는 메모리 공유를 합니다.
- 스레드는 가볍고 빠르지만, 동기화 문제가 발생할 수 있습니다.
꼬리질문 1 : 스레드끼리 메모리를 공유하면 어떤 문제가 생기나요?
- 여러 스레드가 같은 메모리를 동시에 수정하면 데이터 충돌이 발생할 수 있습니다.
- 이를 해결하려면 뮤텍스, 세마포어 같은 동기화 기법을 사용해 순차적으로 접근하게 해야합니다.
명령어 사이클(Instruction Cycle)이란 무엇인가요?
- 명령어 사이클은 CPU가 한 명령어를 처리하는 일련의 과정입니다.
- Fetch : 명령어 가져오기(PC가 주소 지정)
- Decode : 명령어 해석(CU가 해석)
- Execute : 명령어 실행(ALU/레지스터)
- Write-back : 결과 저장
꼬리질문 1 : 이 과정에서 Program Counter는 어떤 역할을 하나요?
- Program Counter(PC)는 다음에 실행할 명령어의 주소를 저장하는 레지스터입니다.
- 명령어를 가져오면 PC가 1 증가하여 다음 명령어 주소를 가리킵니다.
파이프라이닝(Pipelining)이란 무엇인가요?
- 파이프라이닝은 명령어를 여러 단계로 나누어 동시에 처리하여 CPU 처리 속도를 높이는 기법입니다.
- 예를 들어 Fetch -> Decode -> Execute -> Write의 단계가 있다면, 각 단계가 겹쳐서 실행되므로 여려 명령어를 동시에 처리할 수 있어 성능이 향상됩니다.
꼬리질문 1 : 파이프라이닝의 단점은 없나요?
- 데이터 의존성
- 분기 예측 실패(Branch Hazard)
- 자원 충돌(Resource Conflict)
- 파이프라이닝은 빠르지만, 명령어 간의 의존성, 분기 예측 실패, 자원 충돌 등의 문제로 인해 병목 현상이 생길 수 있고, 이를 해결하기 위한 추가 기술이 필요합니다.